Agüera y Arcas, Blaise. 2022.
“Do Large Language Models Understand Us?”
Dædalus 151 (2).
https://doi.org/10.1162/DAED_a_01909.
Bender, Emily M., Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell.
2021.
“On the Dangers of Stochastic Parrots:
Can Language Models Be
Too Big?”
In
Proceedings of the 2021 ACM Conference on
Fairness, Accountability, and
Transparency, 610–23. Virtual Event Canada: ACM.
https://doi.org/10.1145/3442188.3445922.
Bisk, Yonatan, Ari Holtzman, Jesse Thomason, Jacob Andreas, Yoshua Bengio, Joyce Chai,
Mirella Lapata, et al. 2020.
“Experience Grounds Language.”
arXiv:2004.10151 [Cs], November.
http://arxiv.org/abs/2004.10151.
Bostrom, Nick. 2014. Superintelligence: Paths, Dangers, Strategies. First
edition. Oxford: Oxford University Press.
Breazeal, Cynthia. 2003.
“Emotion and Sociable Humanoid Robots.”
International Journal of Human-Computer Studies 59 (1-2): 119–55.
https://doi.org/10.1016/S1071-5819(03)00018-1.
Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla
Dhariwal, Arvind Neelakantan, et al. 2020.
“Language Models Are Few-Shot
Learners.”
arXiv:2005.14165 [Cs], June.
http://arxiv.org/abs/2005.14165.
Chowdhery, Aakanksha, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam
Roberts, Paul Barham, et al. 2022.
“PaLM: Scaling Language
Modeling with Pathways.”
arXiv:2204.02311 [Cs], April.
http://arxiv.org/abs/2204.02311.
Dennett, Daniel C. 2017.
From Bacteria to Bach and Back: The Evolution of
Minds. WW Norton & Company.
Kaplan, Jared, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon
Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020.
“Scaling Laws for Neural Language
Models.”
arXiv:2001.08361 [Cs, Stat], January.
http://arxiv.org/abs/2001.08361.
Linzen, Tal. 2020.
“How Can We Accelerate
Progress Towards Human-Like
Linguistic Generalization?”
In
Proceedings of the 58th Annual Meeting of the
Association for Computational Linguistics, 5210–17. Online: Association for Computational Linguistics.
https://doi.org/10.18653/v1/2020.acl-main.465.
Lynott, Dermot, Louise Connell, Marc Brysbaert, James Brand, and James Carney. 2020.
“The Lancaster Sensorimotor Norms:
Multidimensional Measures of Perceptual and Action Strength for 40,000
English Words.”
Behavior Research Methods 52 (3): 1271–91.
MacWhinney, Brian. 2000.
The CHILDES Project: Tools for
Analyzing Talk. Mahwah, NJ: Lawrence Erlbaum Associates.
McCoy, R. Thomas, Ellie Pavlick, and Tal Linzen. 2019.
“Right for the Wrong Reasons: Diagnosing
Syntactic Heuristics in Natural
Language Inference.”
arXiv:1902.01007 [Cs], June.
http://arxiv.org/abs/1902.01007.
McCoy, R. Thomas, Paul Smolensky, Tal Linzen, Jianfeng Gao, and Asli Celikyilmaz.
2021.
“How Much Do Language Models Copy from Their Training Data?
Evaluating Linguistic Novelty in Text Generation Using
RAVEN.”
arXiv:2111.09509 [Cs], November.
http://arxiv.org/abs/2111.09509.
Michael, Julian. 2020.
“To Dissect an Octopus: Making
Sense of the Form/Meaning
Debate.”
Julian Michael.
https://julianmichael.org/blog/2020/07/23/to-dissect-an-octopus.html.
Michael, Julian, Ari Holtzman, Alicia Parrish, Aaron Mueller, Alex Wang, Angelica
Chen, Divyam Madaan, et al. 2022.
“What Do NLP Researchers
Believe? Results of the NLP
Community Metasurvey.”
arXiv.
https://doi.org/10.48550/arXiv.2208.12852.
Sap, Maarten, Ronan LeBras, Daniel Fried, and Yejin Choi. 2022.
“Neural Theory-of-Mind? On the
Limits of Social Intelligence in
Large LMs.”
arXiv.
http://arxiv.org/abs/2210.13312.
Sperry, Douglas E., Linda L. Sperry, and Peggy J. Miller. 2019.
“Reexamining the Verbal Environments of
Children From Different
Socioeconomic Backgrounds.”
Child Development 90 (4): 1303–18.
https://doi.org/10.1111/cdev.13072.
Thrush, Tristan, Ryan Jiang, Max Bartolo, Amanpreet Singh, Adina Williams, Douwe
Kiela, and Candace Ross. 2022.
“Winoground: Probing Vision and Language
Models for Visio-Linguistic
Compositionality.”
arXiv:2204.03162 [Cs], April.
http://arxiv.org/abs/2204.03162.
Weidinger, Laura, Madeline G. Reinecke, and Julia Haas. 2022.
“Artificial Moral Cognition: Learning from Developmental
Psychology.”
Preprint. PsyArXiv.
https://doi.org/10.31234/osf.io/tnf4e.



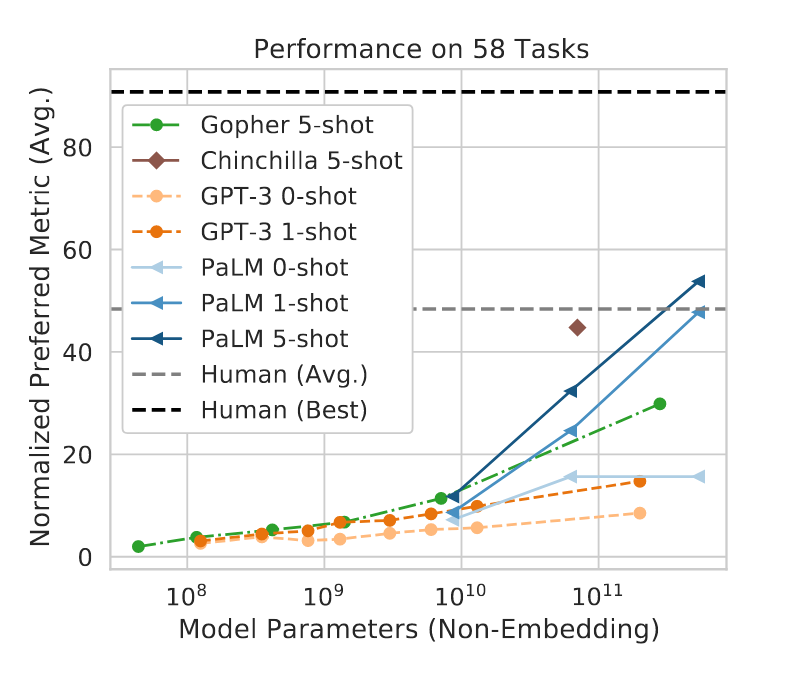

Social domains
Models are only slightly better than chance at theory of mind (Sap et al. 2022).